Problem Formulation#
Learning outcomes#
Construct a computational problem formulation for an English problem statement
Analyze problem formulations in terms of their values
What is problem formulation and why should we care about it?#
Remember the overarching division between “solving problems” (computational thinking) and “coding” (giving instructions to the computer in Python) that we talked about before?
A BIG part of computational thinking is problem formulation.
To do real-world programming, you need to know more than how to write code. You need to be able to take a relatively vague problem like “get all the email addresses out of this file”, and model the problem so that it can be solved by a computer.
An example#
Let’s walk through an example together of what this looks like.
Here’s a vague problem statement: I get so many emails, and i have a blocklist of usernames that i don’t want to see. so, please filter all the emails that come in everyday, so i don’t see the emails from the blocked usernames
And here is a draft decomposition of the overall problem statement that can be part of a problem formulation:
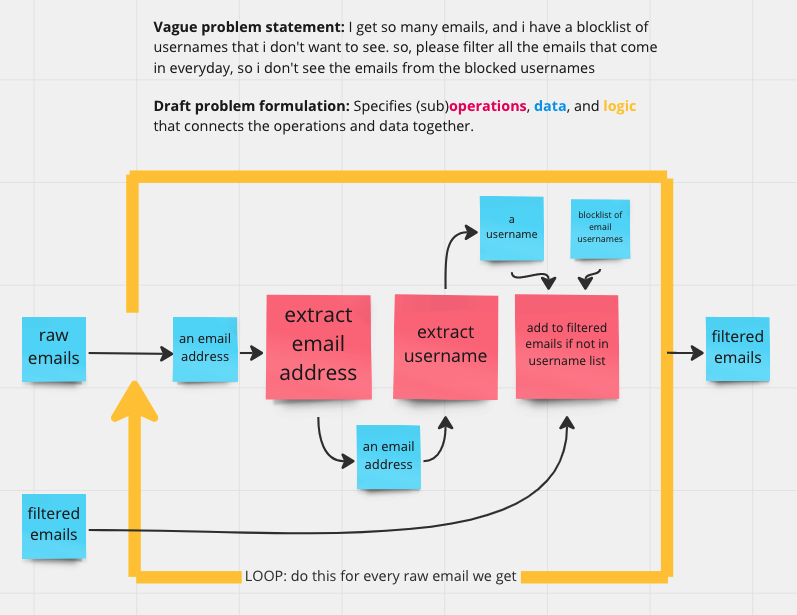
Notice how this formulation is much more detailed in that it decomposes (breaks down) a large and vague problem into smaller (sub)operations, data, and describes the logical relationships between the operations/data.
More on why problem formulation matters#
If you don’t learn this skill (and it is a skill!) in this class, you will struggle in future programming courses (e.g., INST326) and any other area where you’re actually needing to use programming to solve information science problems.
To give a flavor of this, consider this note I got from an INST326 instructor on what students were really struggling with in her class:
“They are struggling with programming in general. Even though this is their second course, they don’t have much ability to think about how to solve problems. We’re in the “I watched everything you did and followed but have absolutely no idea where to start” phase, even with very simple work. I suspect they are sneaking through 126 without learning what they need and suddenly have to create from scratch with me and are panicked”
To emphasize: If you can’t formulate a problem in computational terms, it doesn’t matter whether you know how to write a legal conditional statement, or how to assign variables, and so on. You’ll know how to instruct the computer, but not what instructions to give it! The what comes from problem formulation. It’s absolutely critical!
When/how to do problem formulation?#
You should be able to think through these bits without knowing how to write the code for it yet!
In fact, it’s a really good idea to get started on this before you write any code. Your problem formulation doesn’t have to be perfect or complete, and you will refine it as you go, but it will guide what you write, and help you think through your debugging and help-seeking as well (recall how it’s useful to have a navigator and driver in paired programming: the problem formulation representation can help be a passive navigator resource)
This is why we have your first deliverable for Project 2 be a problem formulation.
Two components of a problem formulation: Decomposition and Specification#
Decomposition#
One key aspect of a computational problem formulation is a problem decomposition:
The key steps/operations of your program
The data that is going in and out of the steps/operations
The logical flow of how all the pieces fit together
Let’s see how these map to our initial example:
In this example, the key elements were:
Operations: extract email address from email record, extract username from email, add email to filtered emails list if the username isn’t in the blocked username list
Data: raw email list, filtered emails, etc.
Logic: loop over every raw email, conditional for the adding operation, sequence between the operations.
In this class we will use a simple diagramming convention of red post-its for operations, blue post-its for data, and orange/yellow for logical relationships. This is a very simplified convention to get at these key ideas around problem decomposition. In professional practice, there are a number of different diagram types and practices (often involving a whiteboard), such as UML diagrams and other conventions/diagrams.
Here is another simple example: I’m going to give you a list of numbers, and I want you to give me back a list that only has odd numbers in it:
What are the main substeps/operations in this problem?
What data is going in/out of the operations?
What is the logical flow of how they fit together?
Here’s an example problem decomposition for that:

Notice how it is possible to formulate it to think about substeps/operations that we know how to do already (check if number is odd)!
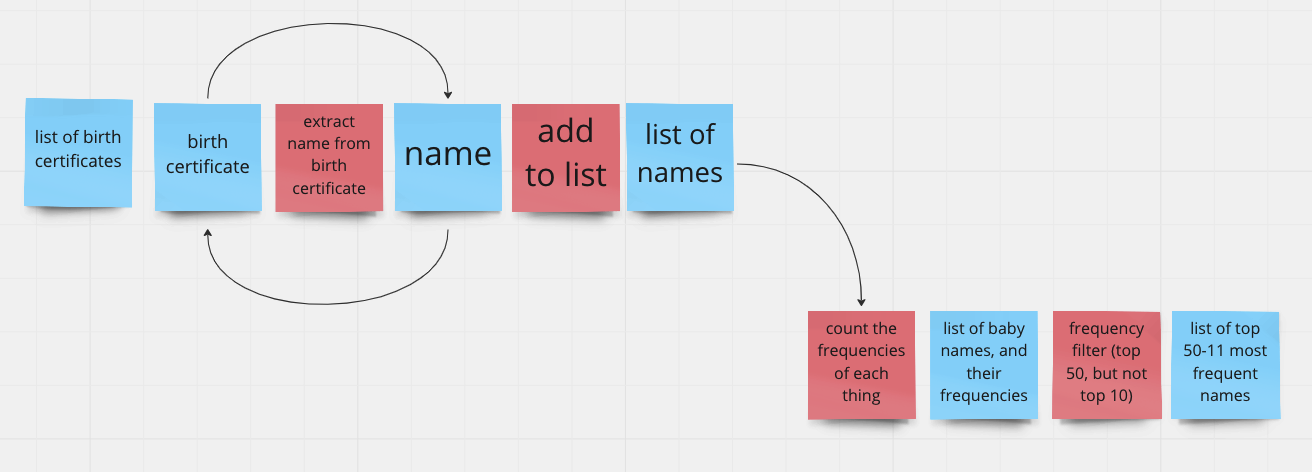
Now let’s look at slightly more complex example that we definitely don’t know how to code yet. I’m going to give you a bunch of birth certificates (N=500,000), and I want you to tell me what the top 50 and top 10 baby names are, because I want to choose names that are recognizable (i.e., in the top 50), but not too common (top 10):
What are the main substeps/operations in this problem?
What data is going in/out of the operations?
What is the logical flow of how they fit together?
Here’s an example problem decomposition for that:
Let’s practice!#
I’m going to give you a list of emails (for people coming into our Zoom room), and I want you to give me back a list that only has emails from @umd.edu:
What are the main substeps/operations in this problem?
What data is going in/out of the operations?
What is the logical flow of how they fit together?
Specification#
A problem decomposition tells you what pieces your program needs. But to actually build (or verify) each piece, you need something more precise: a specification. A specification answers: for a given piece of your program, what should go in, what should come out, and what should happen in different situations?
For example, in our email filter problem decomposition, we identified an operation: “extract username from email.” A specification for that operation would pin down:
Input: an email address string like
"joel@umd.edu"Output: just the username part, like
"joel"Examples of expected behavior:
"joel@umd.edu"→"joel""student123@gmail.com"→"student123"What about
"no-at-sign"? What should happen?
The inputs and outputs are usually the data going in/out of the operations/substeps from our decomposition. But the specification of expected behaviors helps us think more carefully about the operation/substep.
Writing out concrete examples forces you to confront edge cases —– unusual or tricky inputs that your English description didn’t address — that your program should address. This is one of the biggest benefits of moving from a vague problem statement to a precise specification. As we’ll see later, this also facilitates debugging and testing!
Let’s look at another example: the “filter odd numbers” problem. The operation is: given a list of numbers, return only the odd ones.
Input |
Expected Output |
|---|---|
|
|
|
|
|
|
|
|
Notice how the last two rows cover edge cases: a list with just one item, and an empty list. These are exactly the cases that cause bugs if you don’t think about them upfront!
Why bother with examples?#
They expose ambiguity. If you can’t agree on what the output should be for a given input, your problem formulation has a gap.
They can become your tests. Once you write code, you can check it against your examples to see if it actually works. (We’ll formalize this later as “testing.” This is a key part of professional software engineering practice, sometimes called test-driven development).
They help you communicate. If you’re asking someone for help — a classmate, a TA, or even a collaborator — showing them your input/output examples is one of the clearest ways to explain what you’re trying to do.
Practice: write specification examples#
Go back to the “filter UMD emails” practice problem above. Write at least 4 rows in an input/output table, including at least one edge case.
What makes for a good problem formulation?#
IME problem formulation is more of an art.
Here are some heuristics I look out for:
Detailed enough that you start to be able to map them to functions or bits of code that you know how to write. This is called recognizing patterns, and is a key aspect of computational thinking.
Allows you to write and test parts of your problem in isolation from others. You can work on small pieces of code, verify that they work (with your specification), then piece them together into the larger program, instead of trying to write and test a giant program all at once.
You can describe concrete examples of what each piece should do: “if I give it this input, I should get that output.” If you can’t come up with examples, the formulation is probably still too vague.
More helpful Google / Stack Overflow search results
I also look for these affective/emotional/high-level senses:
I feel like I can see the logical “structure” of my program.
The problem feels more managable: I recognize pieces I know how to tackle, and the ones I don’t are specific in ways that makes it easier to learn / seek help
Beyond the “purely technical” for problem formulation#
So far we’ve focused on making problem formulations more precise — clear enough to specify exactly what the program should do. But precision isn’t the only thing that matters. Good problem formulation should also consider what we choose to build in the first place, and how our choices affect the people who use what we build.
Understanding this is a crucial part of being a professional information scientist and programmer.
Values show up in your specifications#
One dimension of this is that your specifications encode values, whether you notice them or not. When you write a spec — defining what counts as valid input, what the expected output should be, what edge cases to handle — you are making choices that reflect deeper assumptions about what matters.
Values are not the same as “features” (i.e., parts of a system). Values are higher-level constraints and conceptions of what counts as “Good” — things like efficiency, cost-saving, performance, privacy, security, harm-reduction, equity. They shape your specifications (what counts as “correct” or “valid”), which in turn shape your decomposition (what you build). So values ultimately determine what gets built (or not).
Let’s see this in action with an example.
Example: data validation for a form#
Consider a form for data entry for payment. One of the operations in your decomposition might be: “validate the name.” That sounds straightforward. But what does “valid” mean? That’s a specification question.
One way to specify it: a valid name is between 2 and 20 characters, ASCII letters only.
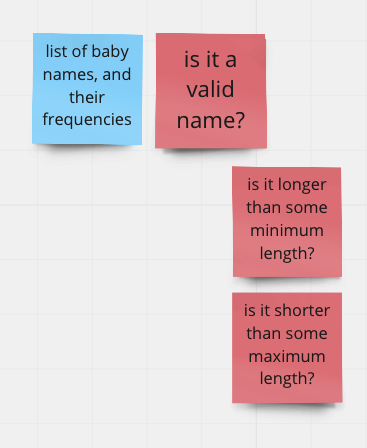
This is how many real-world systems are actually set up. And it works a lot of the time! But look at what this specification assumes: that names are short, that they use only English letters, and that they follow a “first name / last name” structure.
I’ve actually experienced this personally! My “first name” (which includes my Chinese given name “Chu Sern” and my English given name “Joel”) is too long for many government data entry forms!
The specification itself — “valid name ≤ 20 ASCII characters” — is where the value choice happens. It implicitly prioritizes simplicity over inclusion.
This example illustrates why edge cases in your specifications matter so much. Edge cases are often where values show up most clearly, because they’re about who or what gets included vs. excluded. A spec that doesn’t consider the edge case of a very long name, or a name in a non-Latin script, is encoding a value — perhaps unintentionally — about whose names “count.”
Values shape decomposition#
Once you change the spec, the decomposition has to change too. If your specification says “names can be any length, in any script, in any cultural order,” then your decomposition needs:
Different “red” operations (validation rules that handle Unicode, variable lengths)
Different “blue” data structures (perhaps “family name” and “given name” fields instead of “first” and “last”, to accommodate cultures where family name comes first)
In other words, values reshape what counts as correct behavior (your spec), which then determines what operations and data your program needs (your decomposition).
A larger example: contact tracing#
Let’s see this play out at a bigger scale. Consider a contact tracing system for UMD students. The high-level decomposition might look similar across versions — collect data, identify contacts, notify people. But the specifications differ dramatically depending on what values are prioritized.
If you value accuracy: your spec for “close contact” might be strict (within 6 feet for 15+ minutes, verified by multiple data sources). This leads to decomposition with detailed data collection and cross-referencing operations.
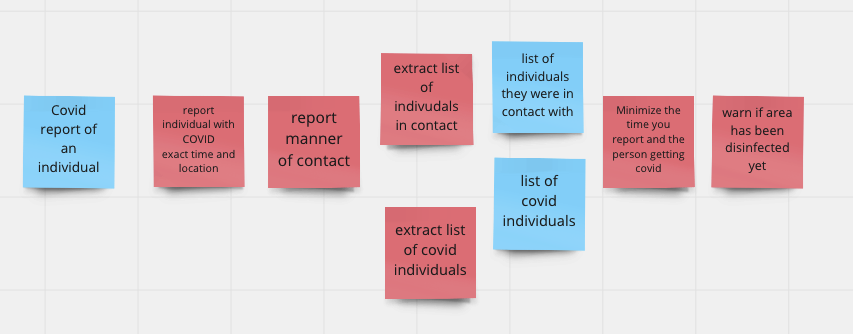
If you value efficiency: your spec might prioritize speed of notification over precision. This leads to decomposition with an alerting operation that emphasizes fast messaging.
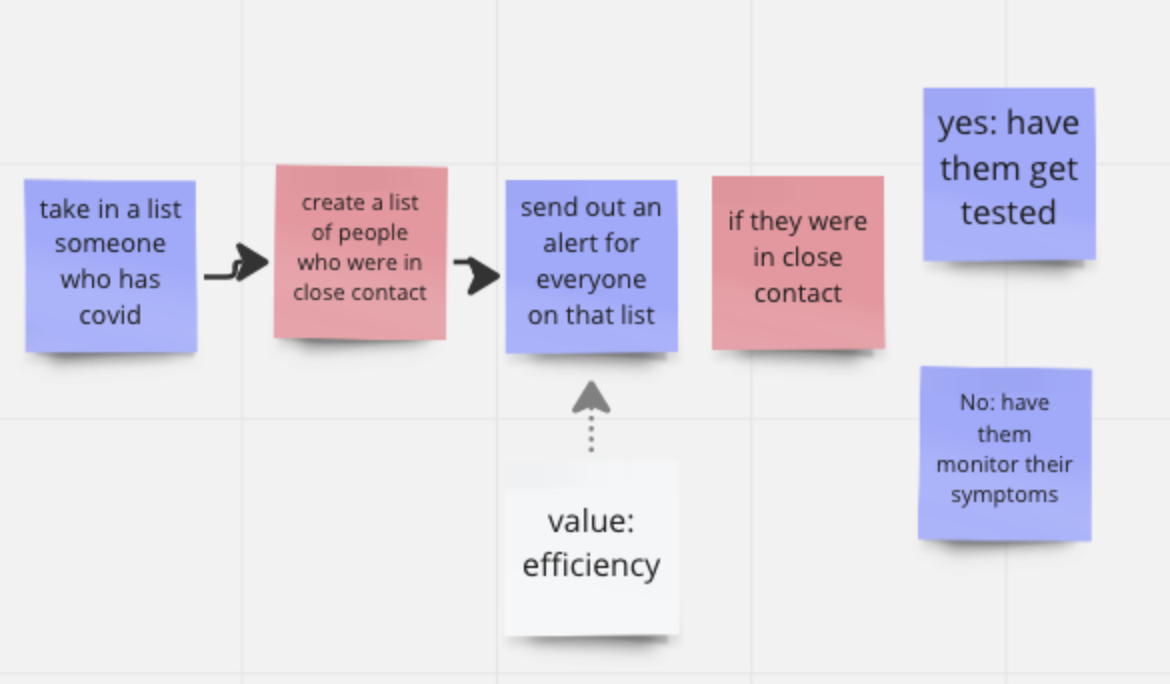
If you value inclusion: your spec might define the system’s scope to include people without easy access to testing. This leads to decomposition with additional operations and data for providing free testing, recognizing that there is unequal access to testing.
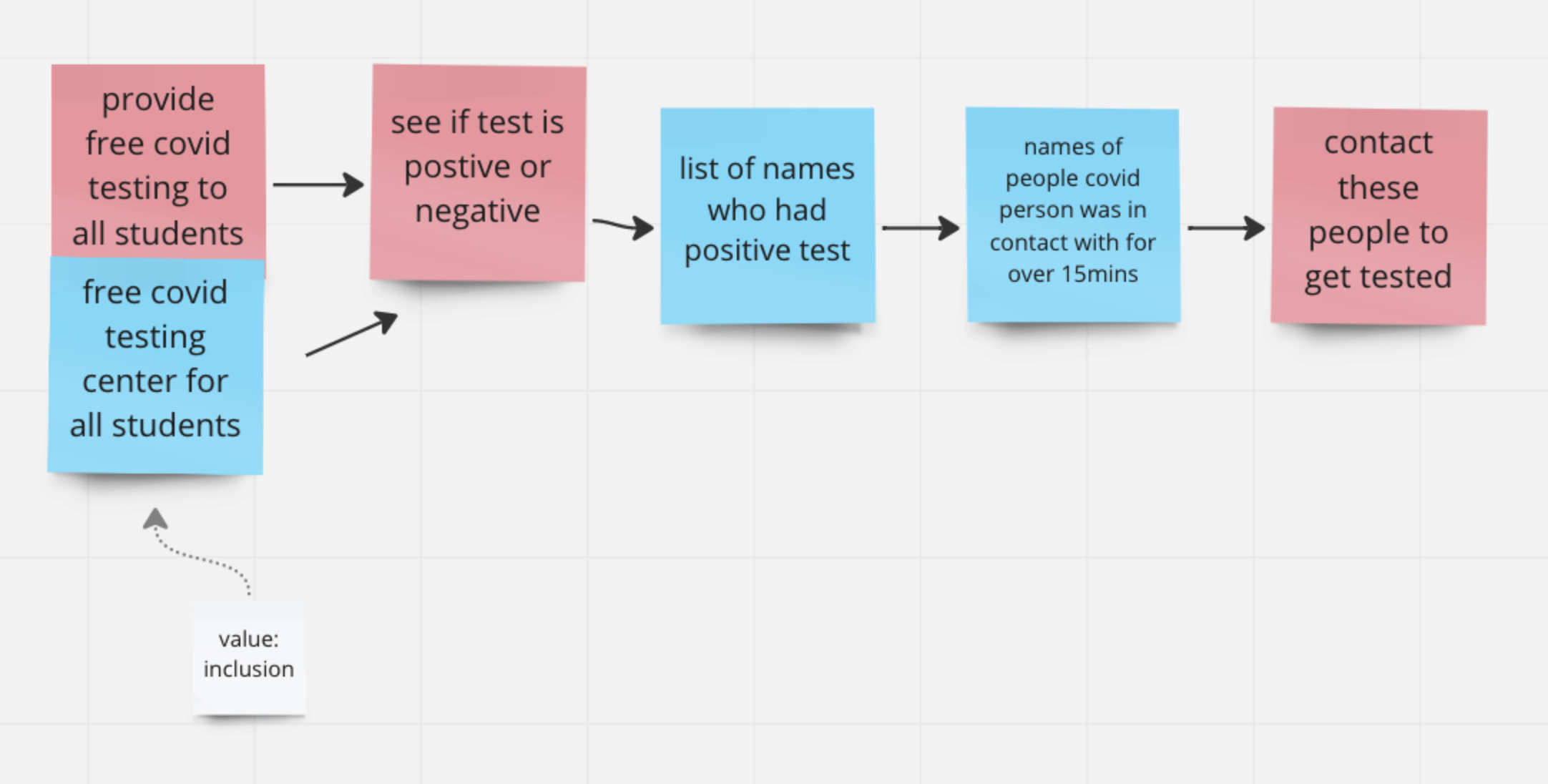
You can imagine yet more variations, such as a version that scans a QR code to report any case of COVID-19 for anonymity reasons (if privacy is a core value).
Notice the pattern: in each case, the value (accuracy, efficiency, inclusion, privacy) shapes how you specify what the system should do, and those specification choices then ripple into what operations and data structures appear in the decomposition.
Recognizing (and being deliberate) about values in problem formulation (and programming)#
A key idea is that problem formulation involves values, whether you notice them or not. This will come up in more or less mundane settings, from data analysis (what counts as “extreme values”, what does “clean data” mean, what is in/out of the dataset), to visualization (do you encode as an explicit step a way to make the visualization accessible?).
Sometimes not recognizing that these values are shaping your design decisions can lead to unintended consequences and harm for people whose values were not represented in your problem formulation. Sometimes a value isn’t so much missing altogether as deprioritized heavily in favor of something else, often unintentionally.
For example, there is a big difference in your experience as a woman or POC on social media if you have scalable ways to block or bar unwanted attention, vs. just a manual process of individually blocking each interaction or even person. To get around this, people have hacked together blocklists and other workarounds to stem the often unbearable torrent of abuse. Do you think that, say, Twitter, doesn’t actually value making sure people are not harmed or abused? Or do the engineers perhaps not hold these values in the same way as some of their users?
I’m not necessarily saying that any one value set is better or worse in all cases. Often, it’s contextual. The point is not really to choose the right values (although sometimes it is!). Instead, the point is to recognize that values play an important shaping role, and to make sure that you check whether your values match up with the values of the people who will be impacted by what you build.
We will practice this with your ethics assignment: take a piece of technology (from the news, etc.), and reflect on it: what values do you see encoded in the way they formulated the problem? What values are left out?
Here’s an example of the sort of reasoning we want you to practice:
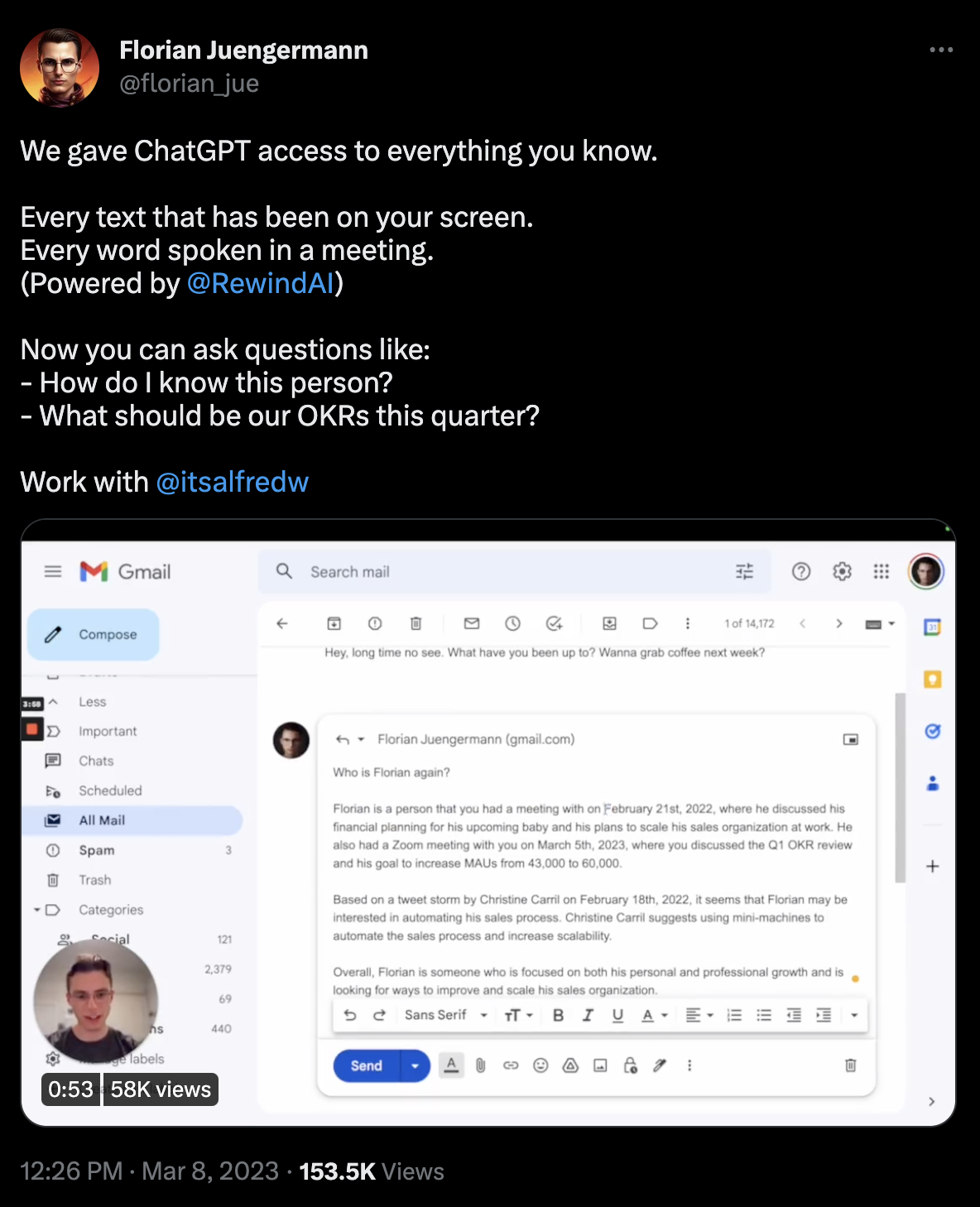
Consider this recent demo of a system for feeding a database of all texts on a screen and audio from meetings (among other sources of data) to build a comprehensive database of “everything you know” or have seen, then giving ChatGPT access to that database to allow you to query it in a user-friendly way. (source in this twitter thread)
Here is a sketch of a problem formulation that is consistent with what was built:
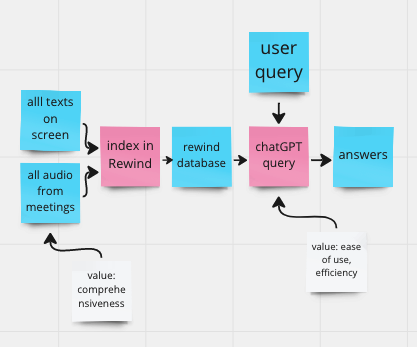
Based on this analysis, here are some draft notes in response to the prompts from the EA assignment, to reflect on what values are in / missing from this problem formulation:
what are the values here? seems like the founder is really excited about giving people an easy to use, efficient way to access and query their knowledge base in a comprehensive manner.
what values are missing, if any? there are no parts of the problem formulation addressing user privacy or data security. contrast this with another related demo that accounts for privacy by having all computations run locally so that data never leaves the user’s machine. there may also be a missing concern for the value of accuracy/correctness. as a large language model, ChatGPT is known to hallucinate answers. in some parts of the demo there are sources cited, but in many other parts answers are just generated w/o clear pointers to sources. there are also no descriptions of correctness checks or mechanisms for verifying answers.